
Race Conditions in Production: Detection, Prevention, and Practical Solutions
Race conditions are not a new problem, but they remain one of the most common issues in systems that scale to millions of requests. Your application may appear to be running correctly, yet the data becomes inconsistent, and you may not immediately understand why.
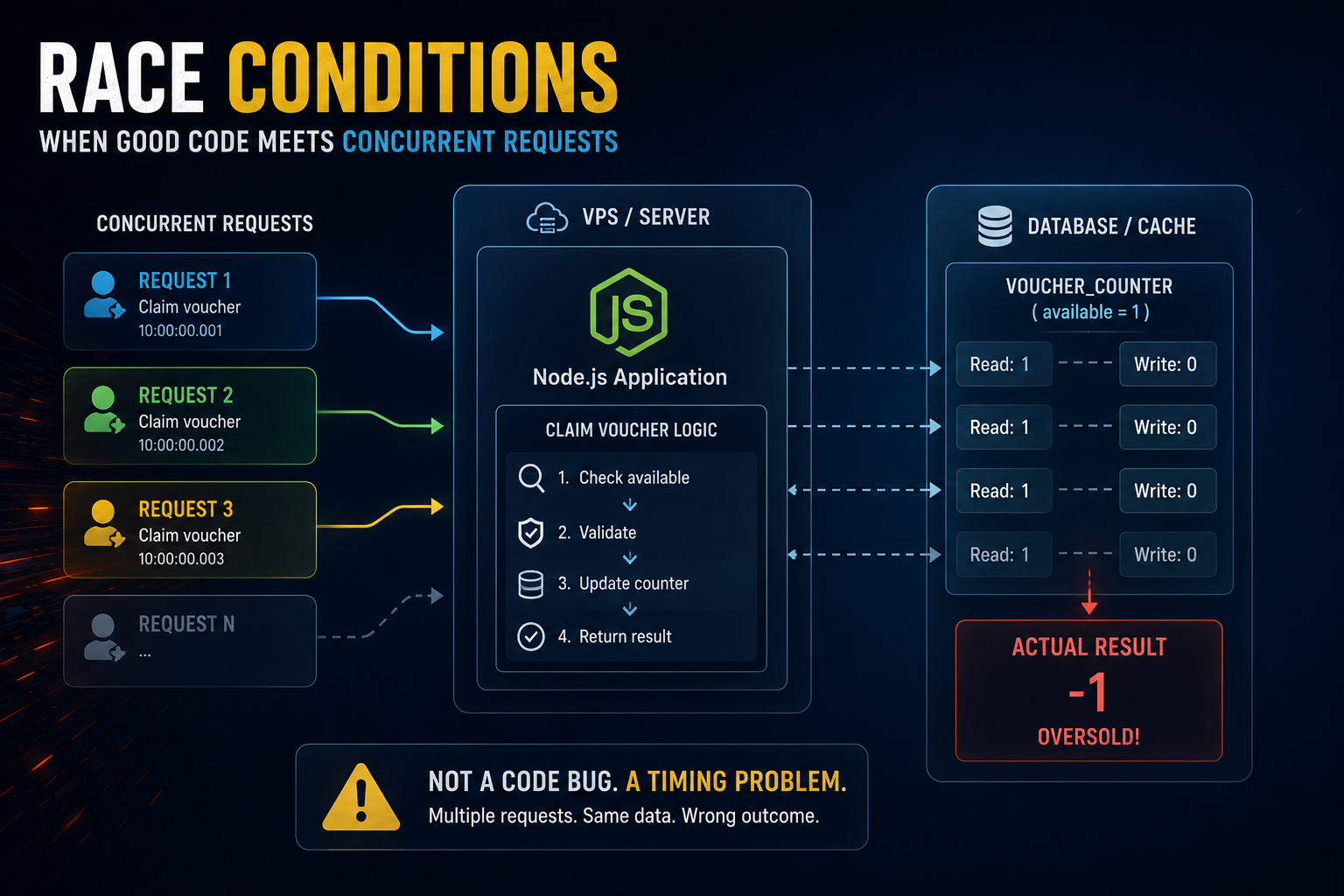
A simple example is an e-commerce application during a sale event. Suppose you have only 100 coupons available, but after the campaign ends, you discover that 103, 105, or even 120 users received a coupon. No error was thrown by the system, but the business logic was violated.
When investigating the issue, you may find that the request handling logic itself is correct. However, the stored data is wrong. The root cause is usually a shared resource, such as a counter, balance, inventory quantity, or cache value.
Consider two requests arriving at nearly the same time. Both requests retrieve the current state before executing the main business logic. The database, cache, or in-memory variable returns the same value to both requests because neither has updated it yet.
If there is only one remaining slot available, both requests may see that slot as available and proceed successfully. Although the requests are separated by only a few milliseconds, they still operate on the same stale data.
Returning to the coupon example, when the system reaches 99 out of 100 available coupons, multiple simultaneous requests may all read the value as 99 and successfully claim the final coupon. As a result, the system may record 99 + N successful coupon claims.
This is a classic race condition.
Common Solutions
1. Atomic Operations
Many databases, caches, and frameworks provide atomic operations that guarantee a read-modify-write sequence is executed as a single operation.
The following example is not atomic:
const value = await redis.get('counter');
await redis.set('counter', value + 1);If multiple requests execute this code simultaneously, they may overwrite each other’s updates.
Redis provides atomic commands such as INCR, which guarantees that the counter is incremented exactly once per request.
Databases also provide atomic update operations. For example, MongoDB offers functions such as findOneAndUpdate() to update a value safely without requiring separate read and write operations.
Use atomic operations whenever possible for counters, inventory quantities, quotas, and other shared values.
2. Database Transactions
Transactions allow multiple operations to be executed as a single unit of work.
If any operation fails, the entire transaction can be rolled back.
BEGIN;
SELECT balance ...
UPDATE balance ...
COMMIT;Transactions are a native database mechanism and should be one of the first solutions considered when dealing with race conditions involving persistent data.
They help ensure consistency and prevent partial updates.
3. Locks
Locks restrict access to a shared resource so that only one request can modify it at a time.
This is a straightforward and effective solution, but it comes with trade-offs:
- Pending requests accumulate while waiting for the lock.
- Response times increase.
- Poor lock management can lead to deadlocks.
Locks are useful when data consistency is more important than throughput.
4. Locks + Semaphores
A semaphore is similar to a lock but allows a limited number of concurrent operations.
Instead of allowing only one request at a time, a semaphore may allow N requests to access the resource simultaneously.
Benefits:
- Better throughput than a traditional lock.
- Reduced contention.
- More flexible concurrency control.
Semaphores are commonly used for rate-limited resources, external APIs, and resource pools.
5. Queues
Instead of allowing all requests to execute concurrently, a queue processes requests sequentially or in controlled batches.
For example:
Request A
Request B
Request C
Request Dbecomes:
A -> B -> C -> DQueues are particularly useful for:
- Payment processing
- Inventory updates
- Order creation
- Email delivery
- Background jobs
The trade-off is increased processing latency.
6. Optimistic Locking
Optimistic locking is one of the most common techniques for preventing race conditions in modern applications.
It uses a version field (or timestamp) to detect whether data has changed since it was read.
For example, imagine a user updates their account balance from both a laptop and a phone at the same time.
Retrieve Data
Request 1: balance = 100, version = 1
Request 2: balance = 100, version = 1Update
Request 1: balance = 200, version = 2
Request 2: balance = 150, version = 2Assume Request 1 completes first.
The database record is now:
balance = 200
version = 2When Request 2 attempts to update the record, its update condition still expects:
version = 1Since the version no longer matches, the update fails.
In other words, the version field answers the question:
“Is the data I am editing still the same as when I originally read it?”
Instead of a version field, many systems use the updated_at timestamp for the same purpose.
Recommended Approach
When dealing with race conditions, try solving the problem as close to the data layer as possible.
A common order of evaluation is:
- Atomic operations
- Database transactions
- Optimistic locking
- Queue-based processing
- Locks
- Locks + semaphores
Whenever possible, prefer database or storage-level solutions before introducing additional infrastructure or framework-level complexity.
Checklist for Race Conditions
When reviewing a feature, ask the following questions:
Shared Data
- Does this code read or modify shared data?
- Can multiple requests access the same record simultaneously?
- Is the shared data stored in memory, cache, or a database?
- What happens if two requests read the same value at exactly the same time?
Concurrency
- What happens when two requests execute in parallel?
- What happens when ten requests execute in parallel?
- What happens when one thousand requests execute in parallel?
- Is the code safe in a multi-threaded or multi-instance environment?
- Does horizontal scaling increase the likelihood of race conditions?
Read-Modify-Write Patterns
- Am I reading a value, calculating a new value, and writing it back?
- Can another request modify the value between the read and write steps?
- Is there an atomic operation available instead?
Database Safety
- Should this operation be wrapped in a transaction?
- Should optimistic locking be used?
- Does the database already provide a safe atomic update operation?
- What isolation level is required for this use case?
Locking
- Would a lock solve the problem?
- What is the performance impact of locking?
- Could deadlocks occur?
- How long can a lock be held safely?
Failure Scenarios
- What happens if a request crashes halfway through execution?
- What happens if the database becomes temporarily unavailable?
- Can duplicate requests be submitted?
- Is the operation idempotent?
Scalability
- Will this solution still work with multiple application instances?
- Will it work with multiple servers?
- Will it work under peak traffic?
- Can the system recover from inconsistent data?
Final Question
- If two requests arrive at the exact same moment, can the business rule still be violated?
- If the answer is yes, there is probably still a race condition somewhere in the system.